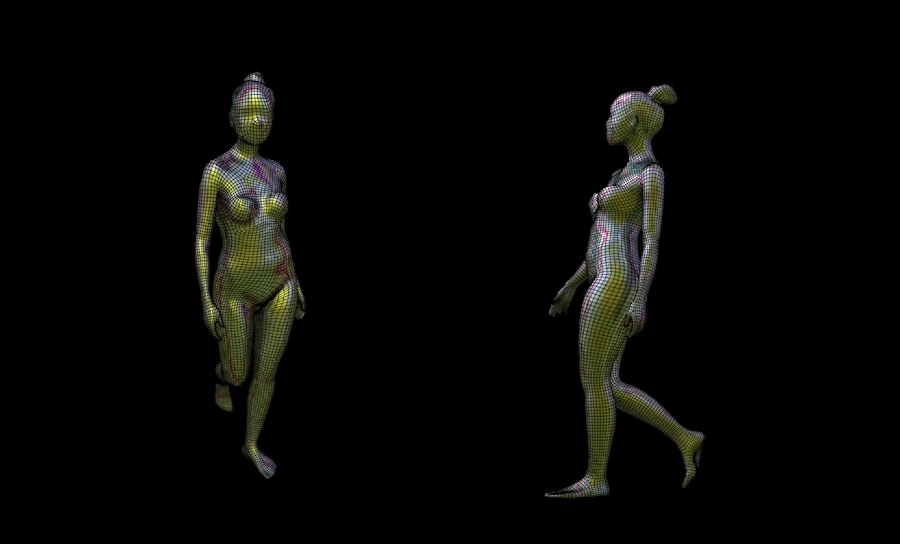
Imagine a world without humans:
Apocalyptic. Landscapes have crumbled. The sun scorches the sand. All creativity dried up in this place long ago. Wild Capture?
Well, they are the technological oasis of creativity planting gardens of green and reinvigorating the soil. Imagine images of a nightclub bred with a laboratory. Think of a digital fashion week runway with an animated human swaggering above a crowd of journalists and debutantes with flickering flashbulbs. Wild Capture is the advanced intuitive space where creators from all walks of VFX and gaming gather to access the technology of volumetric video.
Wild Capture may be the first to be known as a true “digital human company”. They are the technological source pipe-lining nuanced mannerisms, clothes, and human beings to wear them. The recipients are creators who utilize this technological spring-fed tap in the form of extended reality and production services—like the visual energy of Atlanta-based rapper “Latto” projected to an arena display for 19,000 people.
Louis Normandin is the Co-Founder and Chief Operations Officer for Wild Capture. He has twenty-five years of experience in multiple facets of cinematography and production and has worked on three Academy-award-winning films. Louis provided us with a deeper understanding of volumetric video and how translating captured human performances into pristine data sets evokes an experience that is both surreal and vividly alive.
The analogy I think of is that you guys are like potters working with digital clay.
“That’s a perfect analogy. Often times, what our company is doing is providing tools and education so that artists and creators can do more with this digital “clay” as it were.
So much of what Wild Capture does is rooted in the technology of volumetric video. Bringing digital humans to life with lifelike likeness and movement distilled as a 3D model is at the heart of what we achieve.
Once we have captured the human performance, we use those data sets as ground level for our ability to optimize and customize that data. For many years we have developed workflows and pipelines for the different delivery platforms.
Part of our strategy is that by starting with the highest quality assets, we can intelligently compress those data sets so that likeness is preserved for the lower bandwidth deliveries.
Because of the continued development, our non-destructive USD pipeline is leading the way for new creative potential for digital humans in this space. Essentially it functions as an additional layer over the body and allows for things like customizable clothing and VFX layers and is used for our digital crowd system.
Lastly, most of what we do currently comes in the form of product-as-a-service as we continue to distill our technologies into software for artists and creators to have the same toolsets.”
You mentioned capturing the human performance to build data sets that achieve the natural fluidity and motion of a human. If somebody approaches you and asks for say, help with developing a ballroom scene that has sixty dancing humans flowing and gliding in natural movements, how would you begin to develop a project like this? What does the template look like for capturing those movements in a large-scale environment?
“This is a great example.
For a ballroom scene, we could approach it in two different ways. For the more straightforward approach, we would work with the VFX, wardrobe and hair departments to make sure that the talent had the best possible outcome for capture.
As volumetric capture works differently than traditional cinematography, there are new aspects that must be taken into consideration. Things like occlusion (parts of the body that are blocked from certain camera angles) and reflective surfaces can sometimes introduce imperfections in the capture. Hair can also present some of the same imperfections. So we do our best to prevent these issues and promote our best advice for the process.
We also want to consider the action for the scene. It seems like they would be dancing. If so, can we film them separately or can we capture each couple dancing? Resolution for the capture would be divided between the two characters, so depending on what the shots exactly are, this may be OK. Is this a choreographed sequence? If so, we would then need to have a timing or a scratch track available during the production. The essence of our pre-production would tackle all of these types of logistical necessities for capture.
During the volumetric capture, we guide the client and talent through the process to make sure that the best possible capture is obtained. We make sure that they avoid occlusion and data cleanup issues and help facilitate the director’s needs on set. Once production is complete, our team processes that data. Then we begin to clean up, optimize, add the bone structures, uniform, and begin delivery of the polished, optimized data sets.
For larger crowd applications we might utilize our Cohort’s scatter system to automate but for 60 characters, positioning would seem to be more intentional and individually placed.
Of course, the VFX pipeline natively used by the client would be considered. Currently, our assets plug directly into Houdini. As we grow, our plugins will allow these technologies to translate more directly across different 3D software.
If we wanted to scale this into a larger crowd scene, we could go about it in one of two ways. We could duplicate characters with different wardrobe colors to provide variants of the performance. This could work if all of the characters are designed to perform in unison. Otherwise, we could capture the same performer twice to provide a slightly different performance.
Another approach to a much larger scale crowd is to capture our talent in a bodysuit, then add the clothing digitally with our Cohort™ technology. This way, we can use CG cloth to add multiple wardrobe choices digitally to the same performer. Again, we can utilize the same performer for different characters in the scene, depending on how the camera is used. This is how we could streamline data for a 1,000-person scene, as an example.
That’s the nuts and bolts on the overview. This is what Wild Capture is doing for our clients right now. As we grow, we automate these technologies and turn them into software for creators and artists working in this space.”

You mentioned the issue of occlusion. What kind of hardware do you employ to fulfill the best capture possible with the most infinitesimal detail?
“Each volumetric capture stage has its own hardware that is associated with the processing of the initial asset. Once that data set leaves the capture stage’s RAID array, we process the files with our own series of computers that range in processing power. As our systems are designed to power our AI as well as computer graphics, you can imagine that there’s a bit of computing power at our fingertips.
The more computers and people we have to handle the assets, the quicker the pipeline can be. Currently, we work with a very small in-house team working on five different systems to manage the pipeline. This is growing but currently that is a fair assessment.
We also utilize different render engines to support different technical and creative needs.”
Along with the idea of capturing minute detail – how advanced is your ability to capture spontaneous human mannerisms? For example, a client is building an urban environment with a lot of background. A person randomly sneezes on the sidewalk, or a man runs his hands through his hair. Are these occurrences that you already have the technology for, or are working towards?
“It’s always best to capture the intended performances during production so that the visual data is there to pull that part of the performance to use as needed in the scene. It is currently possible to edit two volumetric video clips together as you would 2D video but the technology is not there (yet) to blend different performances together as you would dissolve or comp 2D VFX. While rigged bodies and making changes to the performance is something we provide, face deformation in volumetric video is not there yet.
However, with the ongoing development of our AI, changing the point deformation between two performances will be possible. It’s about getting the AI to interpolate the missing frames of action between performances so that it looks believable. All of this is part of why our company uses AI in our pipeline. Many things are possible.”
What do the stages of that process look like day-to-day for your team, and how many Wild Capture team members does it take to deliver a project of this size?
“Processing times and team size go hand in hand., it’s important to remember that cloud infrastructure and automated pipelines will greatly reduce the timeframes and is always factored into any project budget. That being said, most stages can process anywhere from 12-48 minutes of footage per day depending on settings like textures and FPS. It’s merely a computer just working away in a server room. For the render pipelines and digital human delivery, turnarounds are based on the exact needs of the client and will involve our in-house teams, usually powered by cloud rendering as well.
We’ve spent plenty of time getting some of these stages off the ground. During the production days, it’s usually a team of about 5-7. You have a technical director who runs everything and gives final clearances on all aspects of the system, a system operator who manages the capture process and calibrates the system, a director (sometimes provided by the client), and an assistant director that stays on set with the talent for things like eyeline and technical performance notes. Beyond that, there is usually an executive producer, wardrobe, hair and makeup professionals, and production assistance on set. There can also be rigging and on-set cinematography needs. Often times this team will work in advance of the production so that stage is 100% ready for the client.
From there, Wild Capture passes the data through into the hands of the varied technical and creative artists needed, plus a project manager and/or creative director. Something of this scale could potentially require 5-7 additional artists or developers needed for the post-production pipeline.”
Thanks so much for sharing all your expertise, Louis!




{kind=link}